 +1-480-241-8198
+1-480-241-8198 +44-7428758945
+44-7428758945 +61-1300-332-888
+61-1300-332-888 +91 9811400594
+91 9811400594Are you dealing with duplicate data?
Does your data not fall under exact match?
Are the duplicates in your data not consistent for an exact match?
Are you struggling with cleansing of different types of data duplicates?
If you have answered yes to most or all of the aforementioned questions then the solution to your problem is Fuzzy Matching. Fuzzy matching allows you to deal with the above mentioned problems easily and efficiently.
What is Data Matching?
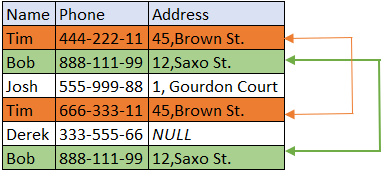
Data Matching is the process of discovering records that refer to the same data set. When records come from multiple data sets and do not have any common key identifier, we can use data matching techniques to detect duplicate records within a single dataset.
We perform the following steps:
- Standardize the dataset
- Pick unique and standard attributes
- Break dataset into similar sized blocks
- Match and Assigning weights to the matches
- Add it all up — get a TOTAL weight
What is Fuzzy matching?
Fuzzy matching allows you to identify non-exact matches of your dataset. It is the foundation of many search engine frameworks and it helps you get relevant search results even if you have a typo in your query or a different verbal tense.
There are many algorithms that can be used for fuzzy searching on text, but virtually all search engine frameworks (including bleve) use primarily the Levenshtein Distance for fuzzy string matching:

Levenshtein Distance: Also known as Edit Distance, it is the number of transformations (deletions, insertions, or substitutions) required to transform a source string into the target one. For example, if the target term is “book” and the source is “back”, you will need to change the first “o” to “a” and the second “o” to “c”, which will give us a Levenshtein Distance of 2.
Additionally, some frameworks also support the Damerau-Levenshtein distance:
Damerau-Levenshtein distance: It is an extension to Levenshtein Distance, allowing one extra operation: Transposition of two adjacent characters:
Ex: TSAR to STAR
Damerau-Levenshtein distance = 1 (Switching S and T positions cost only one operation)
Levenshtein distance = 2 (Replace S by T and T by S)
How to Use Fuzzy Matching in TALEND?
Step 1: Create an Excel “Sample Data” with 2 columns “Demo Event 1” and “Demo Event 2”.
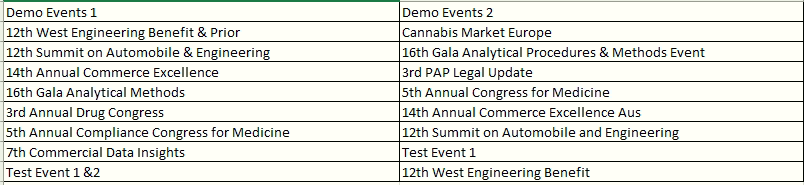
- Demo Event 1: This column contains the records on which we need to apply Fuzzy Logic.
- Demo Event 2: This column contains the records that need to be compared with the Column 1 for Fuzzy match.
Step 2: In TALEND use the above Excel as input in the tfileInputExcel component and provide the same file again as input to the same component as shown in the diagram.
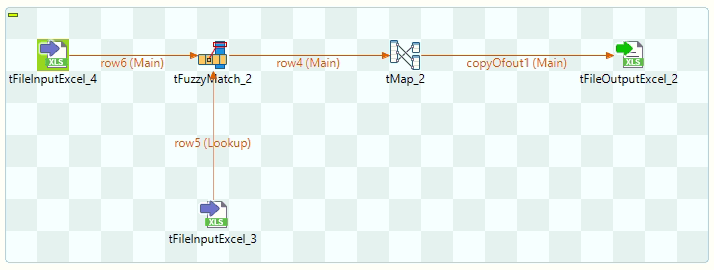
Step 3: In the tFuzzyMAtch component choose the following configurations as shown in the below diagram.
Step 4: In the tMap we need to choose the following column to take an output.

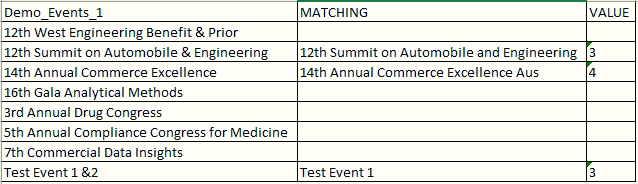
- Demo_Events_1
- MATCHING
- VALUE
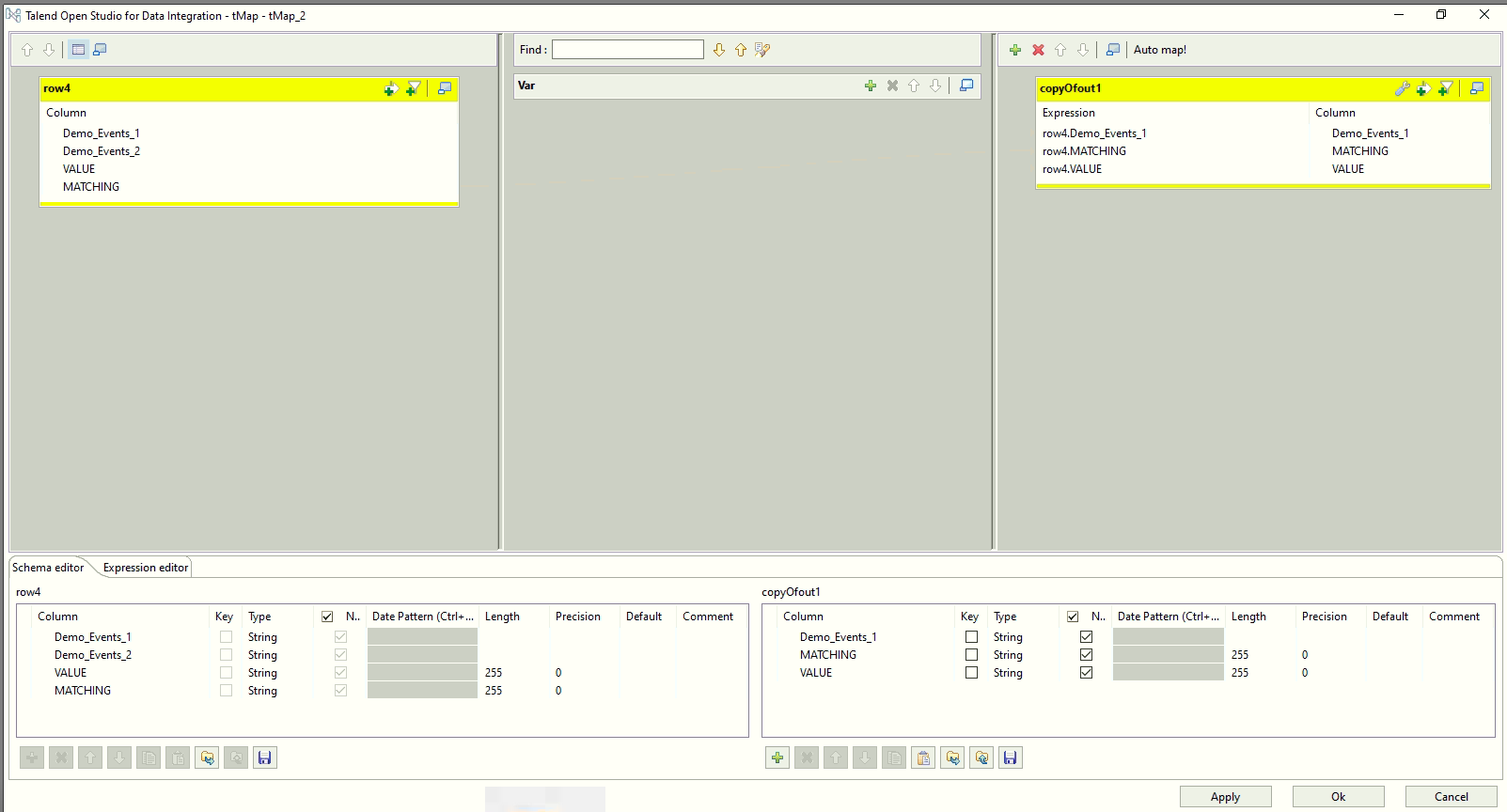
Step 5: Finally, you need to select an tFileOutputExcel component for the desired output.
In the final Extracted file, the Column “VALUE” shows the difference between the records and matches the records to their duplicate.
Conclusion:
In a nutshell, we can say that the use of TALEND’s Fuzzy Matching helps in ensuring the data quality of any source data against a reference data source by identifying and removing any kind of duplicity created from inconsistent data. This technique is also useful for complex data matching and data duplicate analysis.
About Girikon
Girikon is a reputed provider of high-quality IT services including but not limited to Salesforce consulting, Salesforce implementation and Salesforce support.
About Author

Ayush is a Salesforce consultant and Talend Developer with expertise in Data Analysis, Data Migration, and Salesforce Administration jobs. He loves to shares his insights by blogging around ‘Data analysis and various migration techniques’.
Share this post on:



